1 Introduction
The FAIR principles provide a vision of a global ecosystem of dynamically interoperable digital objects such as data, services and computing capacity. This vision entails the requirement to provide machines with enough actionable information about the encountered objects so that they can automate as much as possible the object's discovery, access, interoperation and reuse. Therefore, to fully realise this vision, we need an infrastructure capable of supporting the manipulation of digital objects according to the requirements defined by the FAIR principles.
The evolution of the informatics infrastructure happens in incremental and complementary steps. Whenever the challenges presented in one step are addressed, a new set of possibilities emerge and, with them, new challenges. After the emergence of modern computers we felt the need to interconnect them in networks enabling them to exchange information among the other computers in the same network. Once this was settled, a natural next step was to integrate different computer networks, which was achieved on a global scale by the Internet through its Internet Protocol (IP) and TCP/UDP protocols. The Internet allows the transportation of digital packets/datagrams from a source to a destination host across different networks. A given content to be transmitted is broken down in a number of parts named packets. A header is added to each packet containing information necessary to deliver the packet from the source host to its destination. Once all the packets reach the destination, their content is reassembled. Therefore, the Internet does not deal with the content besides transporting it through different networks.
Once the problem of transporting digital content across different networks has been solved by the Internet, the next challenge in interoperability became the interlinking of Internet resources. The World Wide Web solves this problem by defining another protocol named the HyperText Transfer Protocol (HTTP), which provides a mechanism to interrelate resources through hyperlinks. HTTP provides methods to retrieve, create, add, edit and delete Web resources. Web resources are differentiated, with respect to the WWW infrastructure, only by their serialisation formats (MIME or media types), e.g., an HTML page, an XML file, a JPG/GIF/PNG image, a MP4 video, etc. The actual nature of the resources and their relations, i.e., if they represent a given scientific observation, the results of a match or a person, are not considered by the Web infrastructure.
In the digital realm, we constantly interact with different types of entities, or objects. Examples of such objects are software, software code, dataset and metadata, among others. These objects have different natures. For instance, we could argue that a dataset is a collection of data items grouped because they are interrelated somehow while a software code is a set of instructions written in a programming language that are compiled or interpreted by computers that guide their behaviour. Because of their different nature, each one of these types of digital objects require different ways of interaction. In an increasingly complex digital environment automation becomes a necessity and to support it the identification of these different types of digital objects become relevant as well as the qualification of the relations between them. This brings additional requirements to the digital ecosystem, which are not properly covered by the internet and World Wide Web.
The FAIR principles add yet another set of requirements for the aforementioned digital infrastructures. For instance, the first principle (F1) states that metadata and data should be identified by globally unique and persistent identifiers. Related to this, the FAIR principle A1 requires that metadata and data are retrievable by their identifier using a standardized communications protocol. This means that from a given identifier we should be able to resolve it to something related to the identified entity. Identifiers are, normally, an arbitrary sequence of characters. Regarding identifier resolution, we can split the current identification systems into directly and indirectly resolvable identifiers. In the first group, the identifier is formed following the rules of a given resolution protocol and the identifier can be directly resolved. In this approach, the identifier is tidly bound to the resolution protocol. An example of a directly resolvable identifier is the WWW's Uniform Resource Identifier (URI). The identifier https://fairdigitalobjectframework.org/index.html is an URI and can be directly resolved to this document by using the HTTP protocol. In the second group of identification systems, the identifiers are just an arbitrary sequence of characters without encompassing any resolution protocol in the identifier itself. An example of such identification system is the Digital Object Identifier (DOI). A DOI is composed of a prefix and a suffix separated by a forward slash (/). An example of DOI is 10.1000/123456. Since the DOI is not directly connected to any resolution technology, in order to resolve it we have to transform the DOI into a expression that can be resolved. As the Web is the current prevalent communication platform, a given DOI can be resolved on the Web by appending the URL https://doi.org/ and the identifier. In our example, the resolvable Web link for the doi 10.1000/123456 would be https://doi.org/10.1000/123456.
With indirectly resolvable identifiers, unless the type of identifier and how to create a resolvable link from the original identifier is previously known, it is not straightforward to resolve them. Moreover, with both types of identification systems, once we manage to get the resolvable link and try to resolve it, the next challenge is what to expect when the identifier is resolved. Currently we lack a commonly agreed and predictable resolution behavior, which is an obstacle for artificial agents since, in some occasions, an identifier resolves to its target object, some other times to its metadata and other times to a human-readable HTML landing page.
These aforementioned challenges to apply the FAIR principles in the current digital communication infrastructure were the main motivators for the work on the FAIR Digital Object Framework. The framework aims at providing features to allow answering the two following questions in a way that can be interpreted by both machines and humans:
- What is the object that is identified by this identifier?
- How can I get more information (e.g., how to handle it? who can handle it?, what is it allowed to do with it?) about this object?
- What can be done with the object?
- What am I allowed to do with this particular object?
The results of this work are reported in this document.
2 A brief history of Digital Objects, FAIR Digital Objects and FAIR Digital Object Framework
The concept of Digital Object (DO) (in capital letters to denote a particular definition for representing and manipulating digital entities) was introduced by Robert Kahn in the early 1990s. In his work, Kahn, and later other colleagues, define digital objects as the basic entities of a digital system that are stored, accessed, disseminated and managed. They also defined naming conventions for identifying and locating digital objects as well as described services for using object names to locate and disseminate objects, and provided an access protocol.
Later on, the work on DOs has been improved by the definition of the Digital Object Achitecture (DOA) to address the need to support information management beyond just moving information in digital form from one location to another as allowed by the internet. DOA aims at improving interoperability across participating information systems. As defined by the DONA Foundation in its Digital Object Architecture is composed of:
- Digital Object: "a sequence of bits, or a set of sequences of bits, incorporating a work or portion of a work or other information in which a party has rights or interests, or in which there is value, each of the sequences being structured in a way that is interpretable by one or more of the computational facilities, and having as an essential element an associated unique persistent identifier."
- Digital Object Interface Protocol (DOIP): "a simple, but powerful conceptual protocol for software applications (“clients”) to interact with “services” which could be either the digital objects or the information systems that manage those digital objects.". The latest specification of DOIP can be found here.
- Identifier/Resolution Protocol (IRP): "a rapid-resolution protocol for creating, updating, deleting, and resolving identifiers that are globally managed and allotted. Each identifier is associated with a record that clients can resolve to using this protocol.".
- Identifier/Resolution System: the system enables:
- "allotment of unique identifiers to information in digital form structured as digital objects regardless of the location of such information or the technology used to serve such information;"
- "the resolution of the identifiers to current state information about the corresponding digital object, e.g., its location(s), access & usage policies, timestamps, and/or public keys."
- Repository System: "manages digital objects including the provision of access to such objects based on the use of identifiers, and with integrated security. Through the use of identifiers in the access protocol, the repository system abstracts away the details of the storage technologies from the clients enabling a long-lived mechanism for depositing and accessing digital objects. Access to this system is enabled using the DOIP."
- Registry System: "The registry system is a specialized repository system intended to store metadata about digital objects rather than the digital information itself, and typically stores metadata of digital objects that are managed by one or more repository systems. Access to this system is enabled using the DOIP as well."
After the publication of the FAIR principles in March 2016, the idea around the Digital Objects evolved to the concept of a FAIR Digital Object in order to better align the features of DOs with the aspects highlighted by the FAIR principles. Since the FAIR principles put significant importance on metadata, one major addition to the original concept of DO was the introduction of metadata as a particular type of digital object that is used to describe other objects.
The term FAIR Digital Object (FDO) was first mentioned in a publication in November 2018 in the report named Turning FAIR into reality, of the European Commission's 2nd High-Level Expert Group on the European Open Science Cloud (EOSC). In this report the authors state that the FAIR Digital Objects "represent data, software or other research resources" and "must be accompanied by persistent identifiers, metadata and contextual documentation to enable discovery, citation and reuse".
After the publication of the report, the concept of FDO has been constantly discussed and refined in a number of RDA Interest and Working groups, in particular by the Group of European Data Experts (GEDE).
With the experience in designing technologies and approaches for realising the FAIR principles since the original meeting in January 2014, we have identified a number of challenges to accomplish this goal given the current technologic landscape. In May 2019, I experimented combining features from the (FAIR) Digital Objects with some approaches and features from the Linked Data community, in particular the Linked Data Platform. From this experiment the FAIR Digital Object Framework emerged, which combined the predictable resolution behavior of the (FAIR) Digital Object approach, its idea of resolving the identifier into a small set of information about the object; and the techniques from ontology-driven conceptual modeling, Linked Data and Semantic Web to provide machine-actionable semantic descriptions and annotations to the elements of the Framework.
The proposal for the FDOF has been first discussed with Barend Mons and George Strawn. After a few refinement iterations, together with Peter Wittenburg, a series of meetings were organized in Europe, in the USA and online involving a number of stakeholders involved in both (F)DO (Peter Wittenburg, Larry Lannom, Robert Quick and others) and Linked Data (Jean-François Abramatic, Eric Prud-hommeaux and others) efforts. These meetings culminated in a gathering at the Paris Observatory on October 28 and 29, 2019. In this meeting a group of representatives of different research communities, RDA, CODATA, GO FAIR, US NAS and EOSC discussed the proposed approach, considered it a promising candidate for the core technology of the FAIR ecosystem and committed to continue the refinement and evaluation of the framework towards a "running code" phase where a Proof-of-Concept (PoC) is implemented for testing and demonstration. These commitments we formalised in a document called "the Paris Declaration" and signed by the participants of the workshop.
In this context, this document aims at laying the basic description of the FDOF to guide the discussions around the framework and the implementation of the PoC.
3 The FAIR Digital Object Framework model
The FAIR Digital Object Framework aims at tackling some fundamental issues in digital objects' interoperability. As depicted in Figure 1, the FDOF has been designed to be the basis of the FAIR ecosystem. This means that it aims at tackling core issues raised by the FAIR principles regarding the optimal reuse of digital objects. On top of it, applications, data, vocabularies and other types of digital objects can better interoperate. Underneath, the FDOF relies on existent communication infrastructures such as the Web. Therefore, the FDOF builds on top of this communication infrastructures, not replacing but complementing them.

As the Figure 1 indicates, from the base up we increase the freedom to operate. For instance, considering the internet as the communication infrastructure, different types of applications, framework, service and any other type of internet resource can interoperate at the level of the internet-offered capabilities, i.e., the possibility of exchanging packets across different networks. This is only possible when all resources comply with the internet defined standards and guidelines. On top of these basic communication functionality, there is freedom to add new functionality, features and behaviours. In our inverse pyramid, the FDOF adds some of these extra functionality, features and behaviours required by the FAIR principles and, as long as the involved objects comply with its specifications, an increased level of FAIRness and interoperability is achieved. On top of the FDOF, the involved digital objects can add more features to increase even further the interoperability with other objects following the same added specifications.
The set of features added to the underlying communication infrastructure by the FDOF is concentrated in the following areas:
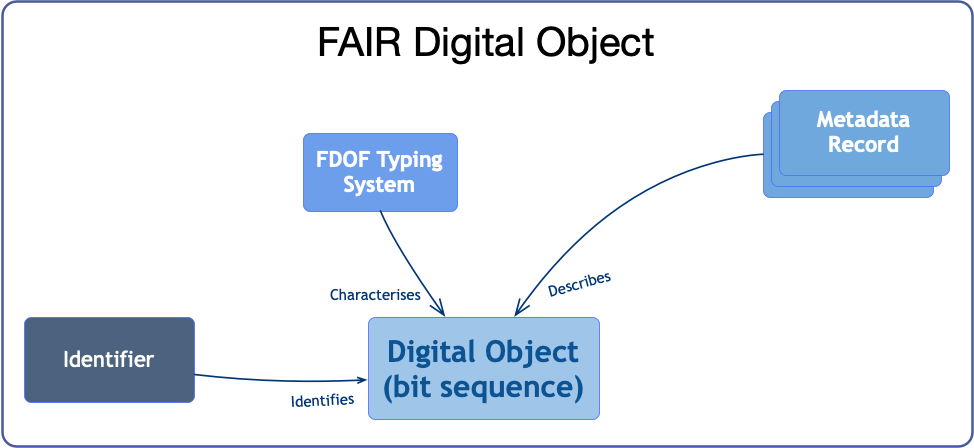
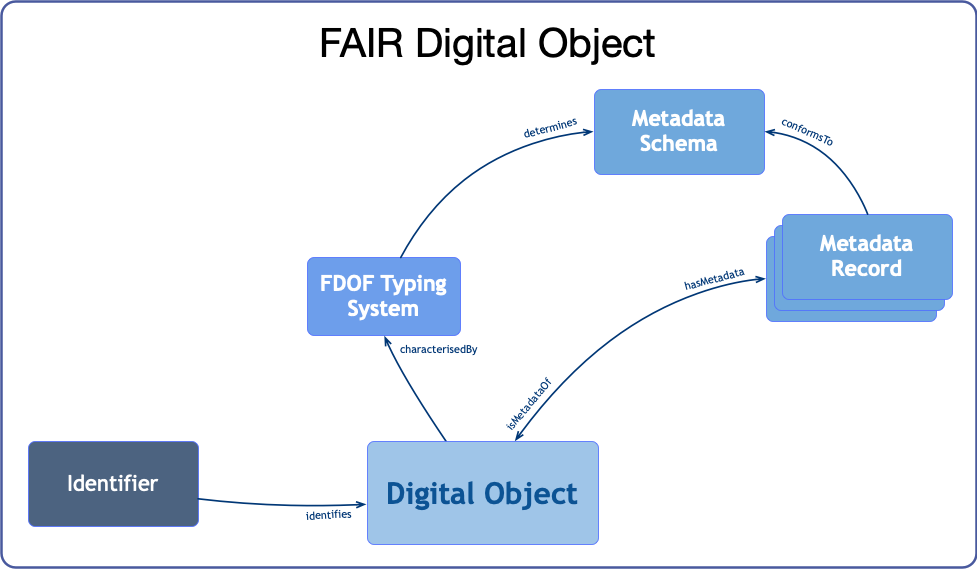
Figure 2 depicts a simplified model for FAIR Digital Objects in the FDOF. When a digital object (bit sequence) is identified by a globally unique, persistent and resolvable identifier, characterised by the FDOF typing system and described by metadata records, we can say that we have a FAIR Digital Object.
3.1 Predictable identifier resolution behaviour
In the context of machine-actionability, it is expected that identifiers of digital objects behave in a predictable way so that the artificial agents can know what to expect when an identifier is resolved. Currently, that is not always the case. Current identification systems (Handle system, URIs, etc.) rely on the user's discipline and best practices. For instance, on the Web, one could use an URI to identify a particular PDF file but the URI may not resolve to anything or it may resolve to something else than the identified object, for instance an HTML page. Similarly, some DOIs (an implementation of the Handle system) resolve the identifier to the actual identified object, some to its metadata and many to a landing page. For artificial agents, landing pages are particularly challenging because it is not always (if ever) clear which of the potentially many links present in the page corresponds to the object identified by the DOI. The DOI example (DOI:10.1109/5.771073) on its homepage (www.doi.org) is the identifier of an article named Toward unique identifiers published by IEEE. From a browser or from a command line curl request, this identifier resolves to the landing page of the paper. In the HTML code of this landing page we can find over a hundred of URLs, including URLs for advertisements on the page. Only one of these URLs refers to the actual PDF file of the article. An artificial client would have difficulties in identifying which of these many URLs points to the object of interest. To tackle this issue, the FDOF defines a predictable resolution behaviour.
In the realm of Digital Objects, each identifier is associated with an identifier record containing so-called state information. There, a client can resolve the DO identifier to this identifier record, which is an artefact containing relevant information about the object.
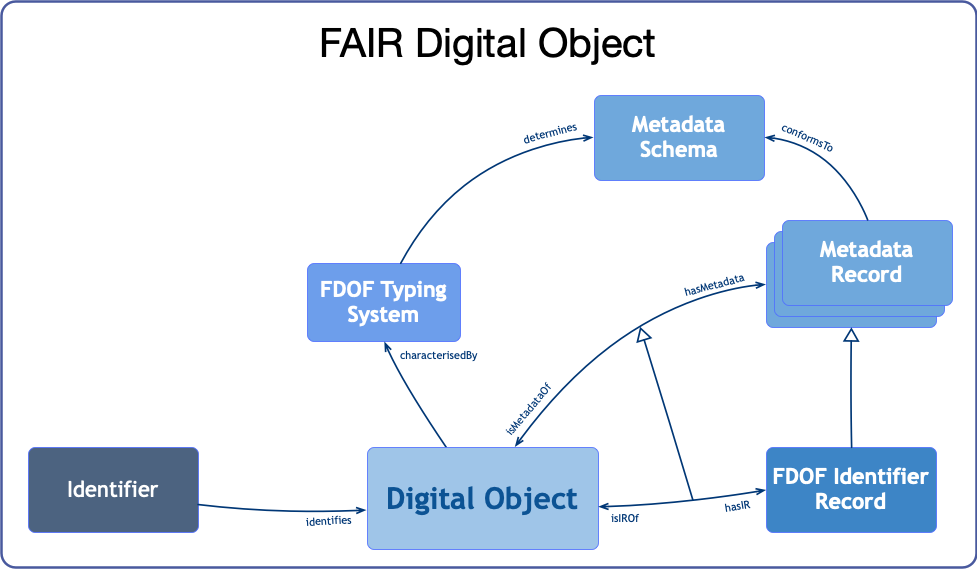
In FDOF, similar to DO, we have an identifier record named FDOF's Identifier Record (FDOF-IR), a specific type of metadata, containing information about:
- The object's type;
- The object's metadata record(s); and
- The object's location(s).
The FDOF-IR is, of course, a specific type of metadata, as depicted in Figure 3. In FDOF we opted to differentiate the three pieces of metadata information contained in the IR from other types of metadata information (e.g., provenance, keys, serialization format, size, etc.). The reason behind this differentiation is to separate the minimal information required by the infrastructure to the additional information that can be used by applications, agreed upon by communities, etc. In this way, we can guarantee that any FDOF-enabled application is able to identify the type of the object (through the reference to the object's type), directly operate on the object (through the object's location reference) or get more information about the object (through reference(s) to the object's metadata record(s)). Other information about the object SHOULD be placed in the metadata record(s).
An identifier is used to identify an object. Therefore, it is natural to expect that the default identifier resolution behaviour resolves to the target object. However, since the Identifier Record provides information about the object that is particularly valuable when the client is not yet familiar with the object, e.g., the client just discovered an object identifier and does not know anything about the object. Because of this, it is relevant for the FDOF to support an additional method to resolve the identifier to its identifier record.
As depicted on Figure 4, the FDOF-IR can be resolved from the object's identifier and present its content using specific predicates to relate the object with its type, its metadata record(s) and its location(s). Moreover, the FDOF does not only provide methods to guarantee a predictable resolution behaviour for the identifier resolution but also defines the format to guarantee predicatability of the metadata presentation format. Therefore, the FDOF-IR MUST be presented as RDF, minimally using the Turtle and JSON-LD syntaxes. This requirement allows not only a predictability of the identifier resolution behaviour but also of the serialisation format of the FDOF-IR, facilitating the implementation of client applications. These client applications would expect to retrieve a FDOF-IR as result of the identifier resolution and can be coded to parse and interpret RDF documents. The choice for RDF as the presentation format for the Identifier Record (and the other types of metadata records) is due to the support of RDF to explicitly provide semantic annotations together with the data content. In this way, the FDOF supports improvements in semantic interoperability and machine actionability.
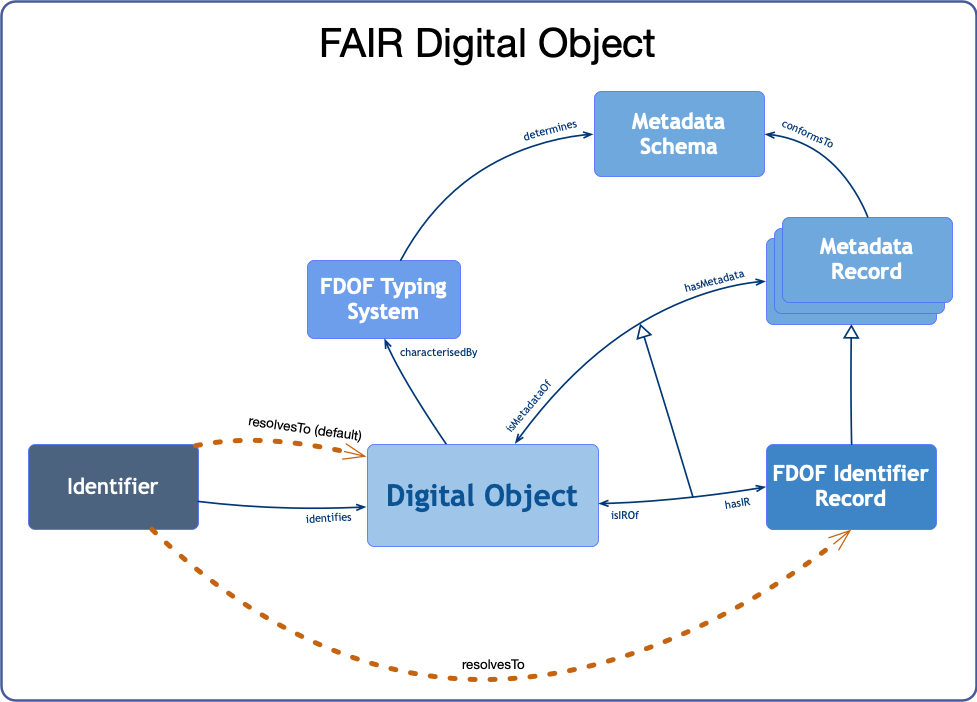
Figure 4 depicts that the identifier can be resolved to either the digital object or to its Identifier Record. Naturally, different resolution methods are used for each case as described in section 3.1.1.
The following code excerpt is an example of the FDOF-IR in RDF turtle serialisation:
<fdofirIdentifier> a fdof-o:fodfIR
fdof-o:isMetadataOf <fdoIdentifier>.
<fdoIdentifier> fdof-o:hasType <FDOType>
fdof-o:hasMetadata <metadataRecordIdentifier>
fdof-o:hasObjectLocation <ObjectLocation> .
...
The FDOF is not intended to replace the current digital communication infrastructure but to complement it providing extra features supporting better machine-actionability to deal with different types of digital objects. Therefore, the FDOF should coexist with these existing infrastructures and, in some cases, leverage their features. To allow a minimum impact on the current communication infrastructure, the FDOF identifier resolution behaviour, as default, resolves directly to the target object. However, the client has the option to request the identifier to resolve to the FDOF-IR instead. Since the FDOF-IR provides information about the object's type and metadata, the FDOF resolution behaviour can also offer methods to directly request these types of information. These methods are just to avoid the need to retrieve the FDOF-IR, interpret it and then get the information. Instead, the protocol described below can directly return the references to the object's metadata records (GETMETADATA) or the object type (GETYPE).
For the extra features of the FDOF identifier resolution behaviour we can implement them by creating an additional protocol which, once evoked, presents these extra resolution features or leverages the current HTTP mechanism for content negotiation.
3.1.1 FDOF resolution protocol
The FDOF protocol (FDOF-P) defines the mechanism to resolve the object's identifier to its FDOF-IR, its metadata or its type. The FDOF-P defines the following methods:
GET
Similar to HTTP, the FDOF-P GET method requests the retrieval of a representation of the specified object.
GETIR
The FDOF-P GET method requests the retrieval of a representation of the FDOF-IR. The default representation of the FDOF-IR MUST be RDF.
GETMETADATA
The FDOF-P METADATA method requests the retrieval of a representation of the object's metadata. The default representation of the metadata record MUST be RDF. The response to the METADATA method MUST be a Linked Data Platform (LDP) container representing the maximal collection of metadata records for the object. This collection contains the references of each of the object's known metadata records. (see the FDOF Ontology section for details)
GETTYPE
The FDOF-P TYPE method requests the retrieval of a representation of the object's type. This representation is a reference to the object's type as defined in the FDOF Ontology or its extension. The default representation of the FDOF-IR MUST be RDF.
Given the identifier example.com/myImageID, we could use the regular Web infrastructure to resolve the identifier directly into my image: GET https://example.com/myImageID. However, if this object is part of the FDOF, its identifier could also be resolved using the FDOF identifier resolution protocol by using GET fdof://example.com/myImageID. In this case, if the client, instead of the object itself, would like to retrieve the object's IR, it could use GETIR fdof://example.com/myImageID.
3.1.2 FDOF-P using HTTP accept headers
Another possibility to implement the FDOF-P features is to use the HTTP accept header parameters. For this we would need to register the FDOF-IR, the FDOF metadata container and the FDOF type description as the following HTTP media types:
- fdof/object - the media type for the object. This media type is the default for the identifier. Therefore, if no specific accept parameter is informed in request, the server returns the actual target object;
- fdof/ir - the media type for the FDOF-IR;
- fdof/metadata - the media type for the object's metadata container;
- fdof/type - the media type for the object's type.
Given the identifier example.com/myImageID, we could use the following curl commands:
curl -H "Accept: fdof/object" -X GET https://example.com/myImageID or,
curl -X GET https://example.com/myImageID. Retrieves the target object of the identifier.
curl -H "Accept: fdof/ir" -X GET https://example.com/myImageID. Retrieves the FDOF-IR.
curl -H "Accept: fdof/metadata" -X GET https://example.com/myImageID. Retrieves the object's metadata container.
curl -H "Accept: fdof/type" -X GET https://example.com/myImageID. Retrieves the object's type description.
Naturally, this approach of using HTTP media types as the mechanism to resolve to the different elements of the FDOS requires the registration of these media types at the Internet Assigned Numbers Authority (IANA). The procedures to register new media types are defined in RFC6838, RFC4289 and RFC6657.
3.1.3 FDOF-P using HTTP Signposting
Closer to the approach using HTTP accept headers defined in the section 3.1.2 and also relying on the HTTP protocol is the use of Signposting. As described in its webpage, Signposting "uses Typed Links as a means to clarigh patterns that occur repeatedly...". In short, Signposting uses HTTP Link header for any type of web resource or HTML link elements for HTML resources to facilitate the identification of relevant links by machines. When navigating through web resources, in special web pages, humans have no problem in identifying links other web resources of interest. However, due to the complete freedom on how to convey such links, machines have difficulties in finding their way around.
Examples of information patterns that can be conveyed using Signposting include:
- Author
- Bibliographics metadata
- Identifier
- Publication boundary
- Resource type
In the Signposting web page, the authors present an example of authorship information being provided in the HTTP header of the web resource at the URL https://doi.org/10.1045/november2015-vandesompel. In this example, the response to an HTTP HEAD against that URL is:
HTTP/1.1 302 found
Server: Apache-Coyote/1.1
Vary: Accept
Location: http://www.dlib.org/dlib/november15/vandesompel/11vandesompel.html
Link: <http://orcid.org/0000-0002-0715-6126> ; rel="author",
<http://orcid.org/0000-0003-3749-8116> ; rel="author"
Expires: Tue, 31 May 2016 17:18:50 GMT
Content-Type: text/html;charset=utf-8
Content-Length: 217
Date: Tue, 31 May 2016 16:38:15 GMT
Connection: keep-alive
Regarding FDOF and Signposting, we could use the approach on the FDO's identifier (URI) providing the links to its metadata record(s) and type information. Similar to HTTP media types, the link types, e.g., author in the previous example, are registered at IANA. These would require that we either reuse existing link types, which may not represent exactly what is intended by the FDOF or registering new link types. The example below present the header of an FDO using the Signposting approach with custom link types.
HTTP/1.1 200
Server: nginx/1.21.6
Content-Type: text/turtle
Connection: keep-alive
Link: <https://fdof.org/object1/fdof-ir> ; rel="fdof-ir",
<https://fdof.org/object1/metadatarecord1> ; rel="fdof-metadata" ,
<https://fdof.org/object1/metadatarecord2> ; rel="fdof-metadata" ,
<https://fdof.org/types/dataset> ; rel="fdof-type"
Accept: text/html, text/turtle, application/ld+json, application/rdf+xml
Expires: 0
3.2 Metadata access mechanism
The FAIR principles dedicate special attention to metadata. All FAIR principles directly relate to metadata and even some of the (sub)principles mentioning data (in practice, any type of digital object) require work on metadata. For instance, in FAIR principle F2 we have that data are described with rich metadata. Therefore, for the data to follow this principle, it is required that we have rich metadata to describe them. In another example, the sub-principle R1.1 states that data are released with a clear and accessible data usage license. The attribution of a license to the data is commonly infomed in the data's metadata.
With such an important role in the FAIR principles, the FDOF naturally provides support for the digital object's metadata. Part of this support comes from the FDOF's metadata access mechanism. In order to facilitate the access to the metadata for client applications, the FDOF provides a common metadata access mechanism so that applications can request access to the metadata of the digital object given its identifier. The usage scenario that illustrates the intended support is that once an identifier has been found, the client application (or its user) may need to gather more information about the identified digital object before deciding whether to deal with the actual object. A common mechanism for such access is important to facilitate interoperability in the sense that any FDOF-enabled client application knows how to access an object's metadata instead of leaving to every service to define their own access mechanisms.
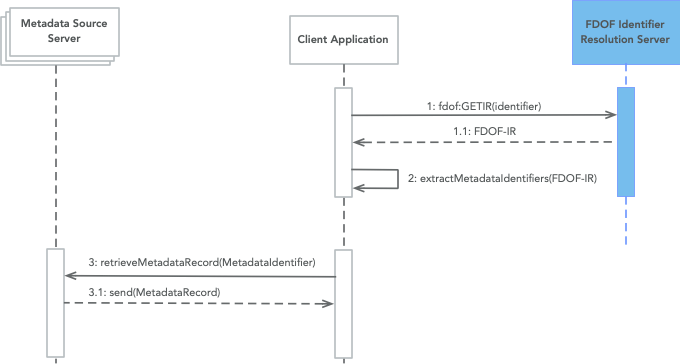
As described in section 3.1.1 and depicted in Figure 4, the client application can directly request the metadata record(s) of the object from its identifier using the GETMETADATA method. This method returns a LDP container representation containing the containment structure having as members all known metadata records for that object (Figure 5).

Another way to obtain access to the object's metadata, as depicted in Figure 6 is through its Identifier Record. Since the IR contains also the LDP container of the object's metadata records, once the application retrieves the IR, it can search in the IR for the references of the metadata records.
3.3 Object typing system
When dealing with objects in general, a common question is "What is this object?". Although seemingly simple, this question may have answers reflecting different aspects of the object. For instance, if we are looking at a photograph, some may say that the object in question is a photo while others may refer to what is the content of the photograph, e.g., a mountain. In the digital world, another relevant aspect to be taken under consideration is the encoding format of the object, e.g., JPG, GIF, PNG, etc.
The question of what can be done with a given object refers to the sorts of operations that can be applied to the object. This involves the type of the object but also the context around an individual objec, including who is intending to perform the operation. For instance, a given object of an specific type my support a set of operations but someone who would like to manipulate that object may not have permission to perform some of the supported operations. Therefore, a typing system that defines operations to objects should have these definitions to both the type and individual levels. The former informs on which operations are applicable to the type of object and the latter deals with permissions of who is allowed to perform these operations.
In the FDOF, the typing system reflects these concerns and provide information about:
- The encoding format of the digital object, e.g., JSON, XML, RDF, JPG, DOCX, etc.;
- The type of the digital object with respect to its informational function, e.g., image, video, dataset, service, etc.;
- The entity(ies) that are represented by the digital object, e.g., the mountain in a photo, a given protein in a protein dataset;
- The operations that are applicable to a given type of digital object; and
- The operations that are allowed to be performed on a specific digital object.
The FAIR principle F2 states that "data are described with rich metadata". This principle, then, defines that metadata have the function of describing digital objects. In practice we have that metadata records contain a set of property attributions that helps describe a given object. Some of these properties may be common to any digital object and some may be specific to certain types of objects.
Since different types of digital objects may be described with different sets of properties, the FDOF typing system can determine specific metadata schemas for specific FDO types, as depicted in Figure 7. A metadata schema defines which properties must or may be present in a given metadata record. One can argue that we will never be able to define a metadata schema that includes all possible properties that are needed for all applications of the metadata. Therefore, in the FDOF, the metadata schemas associated with FDO types define a minimal set of properties. This minimal set of properties guarantee a level of predictability so that users (humans or machines) can expect these properties to be available as descriptors of a FDO of a given type. Naturally, communities, users, object providers or any other stakeholder can add more properties and/or define additional metadata schemas for the FDOs. The more properties, the richer are the metadata records. Once again, the FDOF's type-specific metadata schemas define just a base set of properties that can, and should, be augmented.
TODO: COMPLETE THE OBJECT TYPING SYSTEM WITH THE MODEL FOR OPERATIONS
4 FDOF Core Ontology
NOTE: PLACEHOLDER FOR THE LINK TO THE FDOF CORE ONTOLOGY (FDOF-O) (WORK UNDERWAY)
Acknowledgments
My work on the FDOF did not start and does not continue to happen in a vacuum. As the name of the framework suggests, it has been based on the efforts of many people related to the FAIR and Digital Objects movements. In the DO arena, it started with Robert Kahn defining the initial ideas of Digital Objects followed by Larry Lannom, Robert Quick, Peter Wittenburg and many groups and members of the RDA community refining, expanding, testing and implementing it.
From the FAIR movement side, a growing international community was rapidily formed after the publication of "The FAIR Guiding Principles for scientific data management and stewardship" paper on March 2016 by a group of 54 co-authors, which I am just one of them. In particular, I would like to acknowledge the enormous support and confidence from George Strawn and Barend Mons, our numerous discussions have been instrumental to the current state of the framework. Their involvement, together with Peter Wittenburg, Jean-François Abramatic and others made possible a series of meetings from August to November 2019 where the FDOF was discussed, culminating in the "Paris agreement", where a group representing organizations heavily involved in data stewardship commit to the further evolution of the framework. The development of the FDOF is also heavily influenced by the work conducted by the Linked Data and Semantic Web communities in the past decades having the W3C as their convergence point.